Portfolio
文書分類の前処理
概要
K近傍法で文書分類をしてみようの初回記事
ここでは文書データを機械学習に使えるようにします。
ここでは文書データを機械学習に使えるようにします。
文書データの準備
今回はlivedoorニュースコーパスを使用します。
・livedoorニュースコーパス
9種類のカテゴリーに分かれていて、内容はニュース記事になっています。
ここから全文書を分かち書きして単語辞書を作成します。
分かち書き

単語の間に空白を入れます。(これを分かち書きといいます)
以下のサイトで説明されているように、機械学習をするには事前に分かち書きをします。
・ランサーズの仕事を機械学習で分類する – 2. 分かち書き –
分かち書きにはmecab-ipadic-NEologdを使用しました。
分かち書きには以下のプログラムを使用
・プログラム(分かち書き)
mecab-ipadic-NEologdについて
Web上の言語資源から得た新語を追加することで最近の言葉にも対応できるようにした MeCab 用のシステム辞書です。以下のサイトの説明が非常に参考になりました。
・ 【Python】WindowsのMeCabでNEologdをユーザー辞書に使う
ここからダウンロードできます。
・mecab-ipadic-NEologd : Neologism dictionary for MeCab
単語辞書を作成
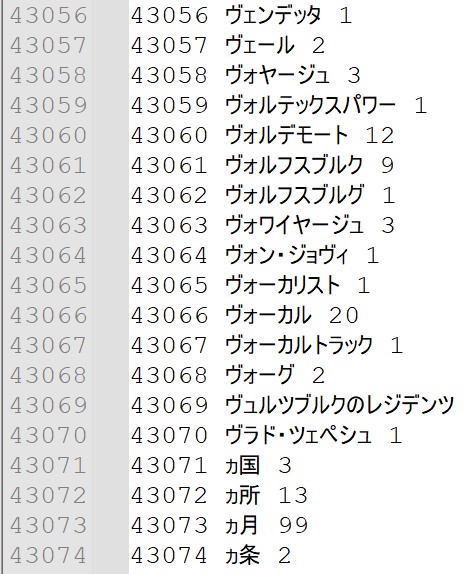
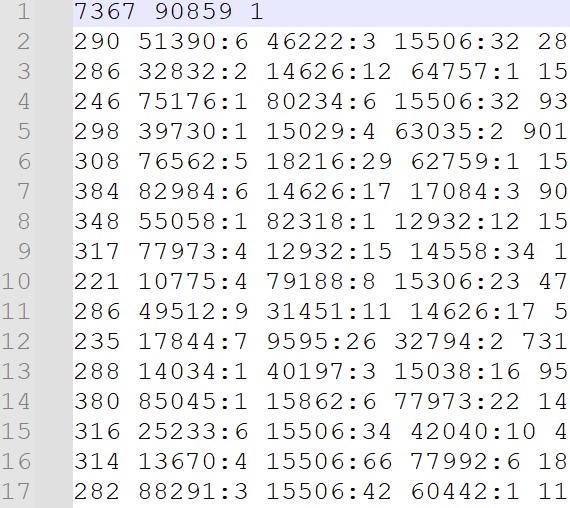
各文書での単語の出現回数も記録しておきます。
一番左の数字が各文書での単語数(種類)です。
その後に[単語ID]:[出現回数]を羅列しています。
各文書での単語出現頻度表の作成には以下のプログラムを使用
・プログラム(単語頻度表)
次回はこのデータを元に各文書・各単語のTF-IDFを算出します。