Portfolio
K近傍法で文書分類
概要
K近傍法で文書分類をしてみようの最終記事
前回は各文書・各単語のTF-IDFを計算しました。
今回はK近傍法で文書分類をします。(K近傍法にしたのは実装が一番簡単そうだったからです)
前回は各文書・各単語のTF-IDFを計算しました。
今回はK近傍法で文書分類をします。(K近傍法にしたのは実装が一番簡単そうだったからです)
定義
K近傍法とは自身の周囲にあるデータがどこに分類されているか集計を取り、多数決で自身の分類先を決定する方法です。
例として、分類先が決まってない文書Xの周囲に以下の文書があるとします。
以下のサイトが参考になりました。
・【5分で分かりやすく解説】k近傍法とは?理論とRでの実装方法!
例として、分類先が決まってない文書Xの周囲に以下の文書があるとします。
- 文書A[dokujo-tsushin]
- 文書B[it-life-hack]
- 文書C[it-life-hack]
- 文書D[sport-watch]
以下のサイトが参考になりました。
・【5分で分かりやすく解説】k近傍法とは?理論とRでの実装方法!
コサイン類似度の計算
定義のとおりで周囲にある文書の分類先を多数決で取るのですが、周囲にある文書が誰なのか把握する必要があります。
そこで使用するのがコサイン類似度です。(計算の際にTF-IDF値も使います)
コサイン類似度を用いることで各文書間での類似度を計算できるので、この値を文書間の距離に置き換えます。
詳細は以下のサイトの方が参考になります。(計算式もこれの通りに実装します)
・コサイン類似度について
そこで使用するのがコサイン類似度です。(計算の際にTF-IDF値も使います)
コサイン類似度を用いることで各文書間での類似度を計算できるので、この値を文書間の距離に置き換えます。
詳細は以下のサイトの方が参考になります。(計算式もこれの通りに実装します)
・コサイン類似度について
K近傍法の実装
以下のプログラムを使用して文書分類しました。(プログラミングめっちゃムズかった...)
・プログラム(K近傍法)
分類結果はこのようになり、正答率は80%でした。
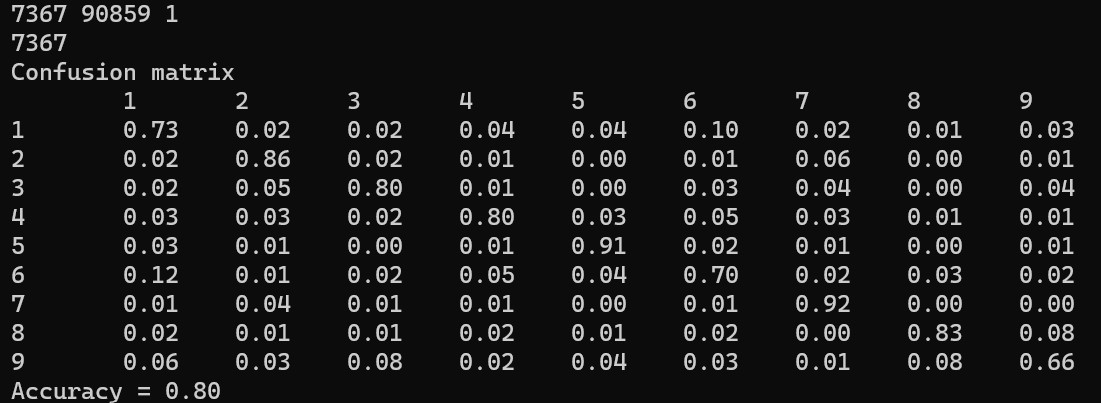
1~9の番号はカテゴリー名を表しています。
次回からは分類精度が低いカテゴリーに着目して分類を間違える原因を分析するつもりです。
(「K近傍法で分類してみよう」の記事はこれで終了です。次回からは研究報告よりの内容になります)
・プログラム(K近傍法)
分類結果はこのようになり、正答率は80%でした。
1~9の番号はカテゴリー名を表しています。
- 1:dokujo-tsushin
- 2:it-life-hack
- 3:kaden-channel
- 4:livedoor-homme
- 5:movie-enter
- 6:peachy
- 7:smax
- 8:sports-watch
- 9:topic-news
次回からは分類精度が低いカテゴリーに着目して分類を間違える原因を分析するつもりです。
(「K近傍法で分類してみよう」の記事はこれで終了です。次回からは研究報告よりの内容になります)