Portfolio
Docker+Djangoでテキストマイニングアプリを作成
アプリ概要
文書データセットから学習データを作成するアプリを作成しました。
何も整形されていないデータセットに分かち書きや単語整形を施して学習データに変換します。
実装コード:Text_Mining_App
そのため予め必要となる機能をアプリにして楽にデータ整形することにしました。
ファイル拡張子は txt, csv, tsv から選択することができます。
開発環境ではsqlite3, 本番環境ではpostgresqlを使用しています。
データセットの二次配布が禁止されているので実装しました。
何も整形されていないデータセットに分かち書きや単語整形を施して学習データに変換します。
実装コード:Text_Mining_App
開発背景
機械学習では、以下の前処理をする必要があります。- 特定のデータ行のみ摘出する
- 特定のデータ列のみ摘出する
- 数字や記号など、意味関数が低い単語を0などの単語に統一する
そのため予め必要となる機能をアプリにして楽にデータ整形することにしました。
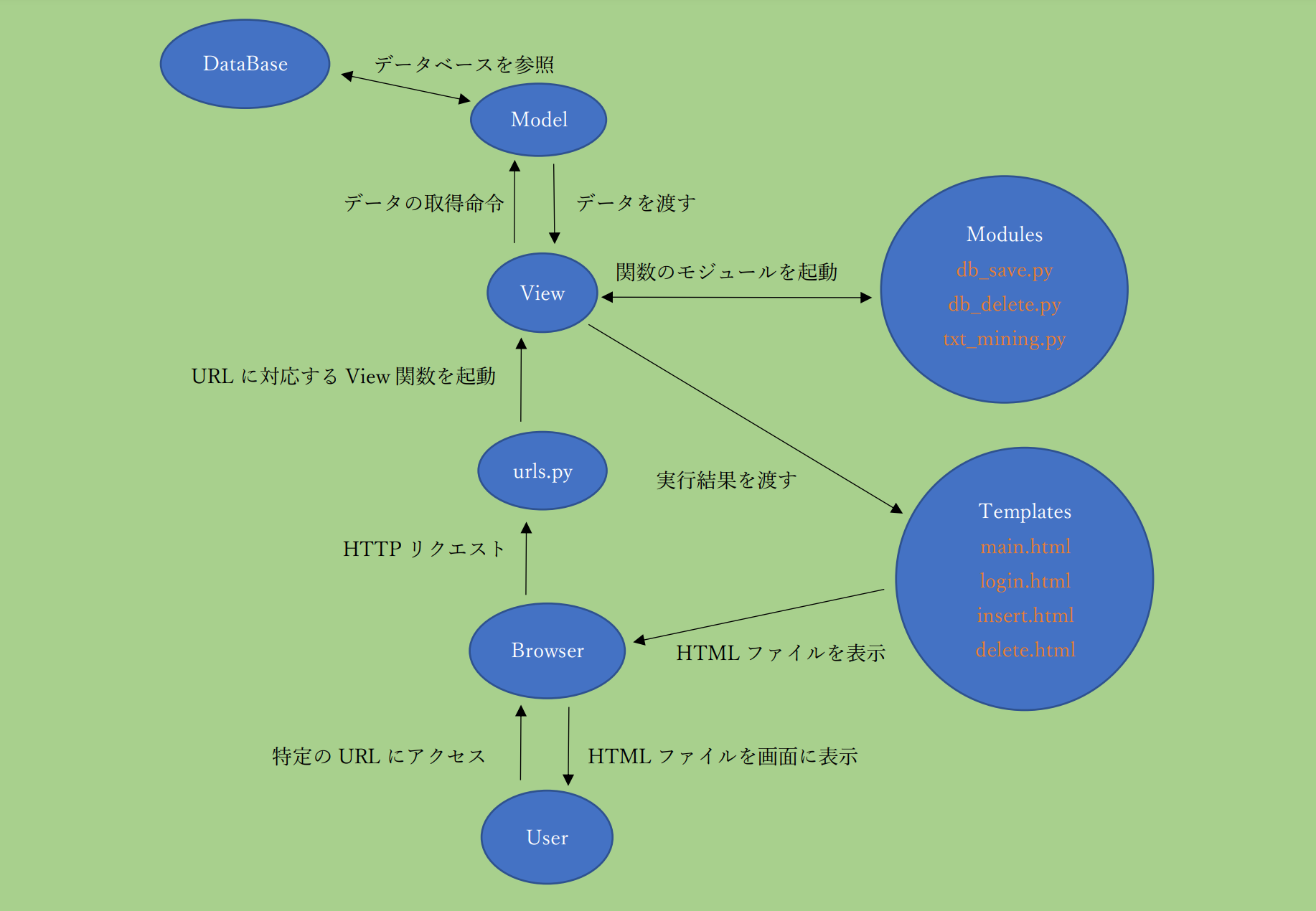
アーキテクチャ
Django の MTV(Model, Template, View) モデルを元に設計しました。- M : データベースと連携を取る
- T : HTMLファイルとして画面に反映させる
- V : Modelから取得したデータの見せ方を定義する
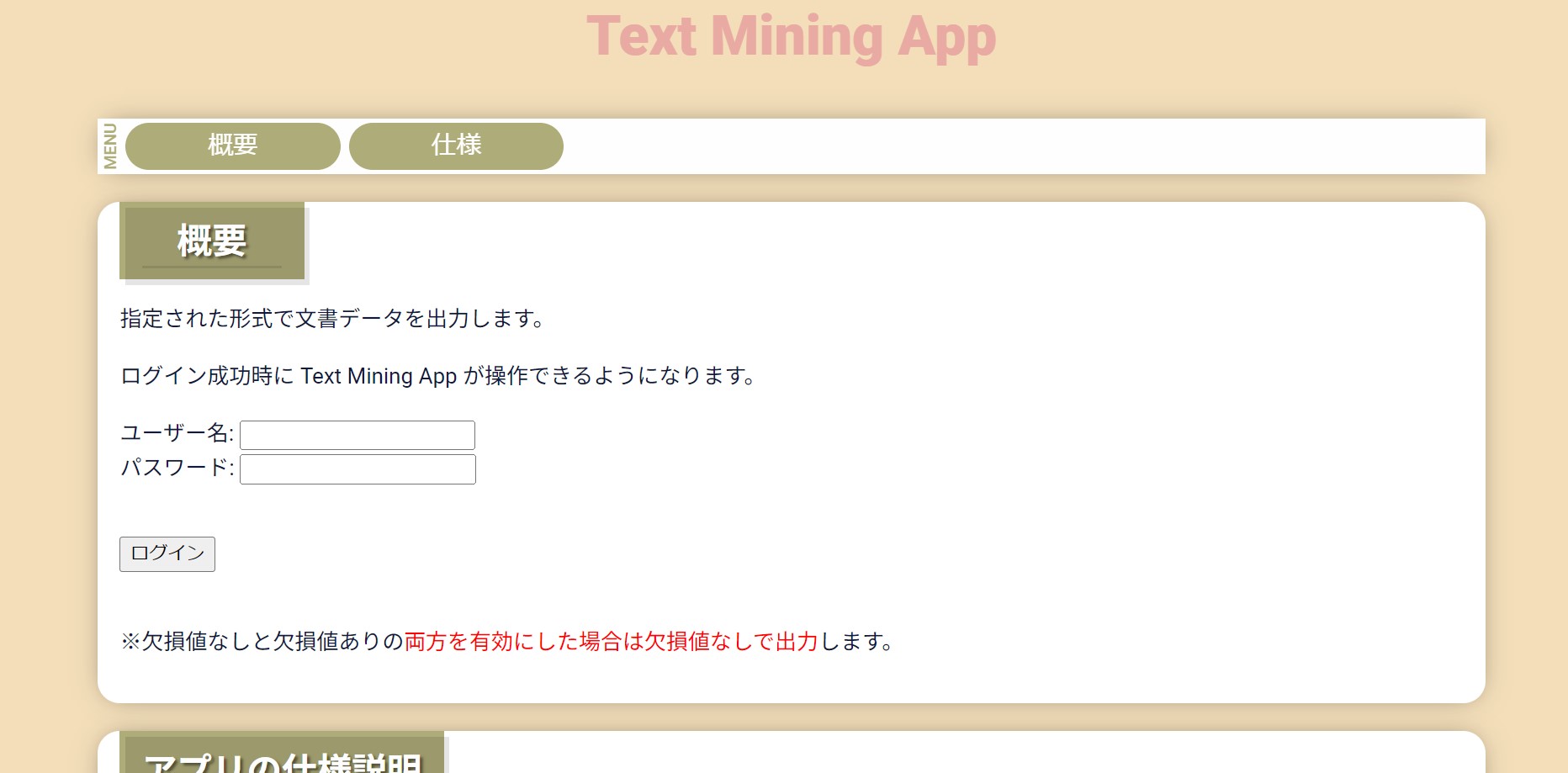
メイン画面
用途に応じた選択肢を選び、「ファイルを作成する」ボタンを押すことで学習データがダウンロードされます。ファイル拡張子は txt, csv, tsv から選択することができます。
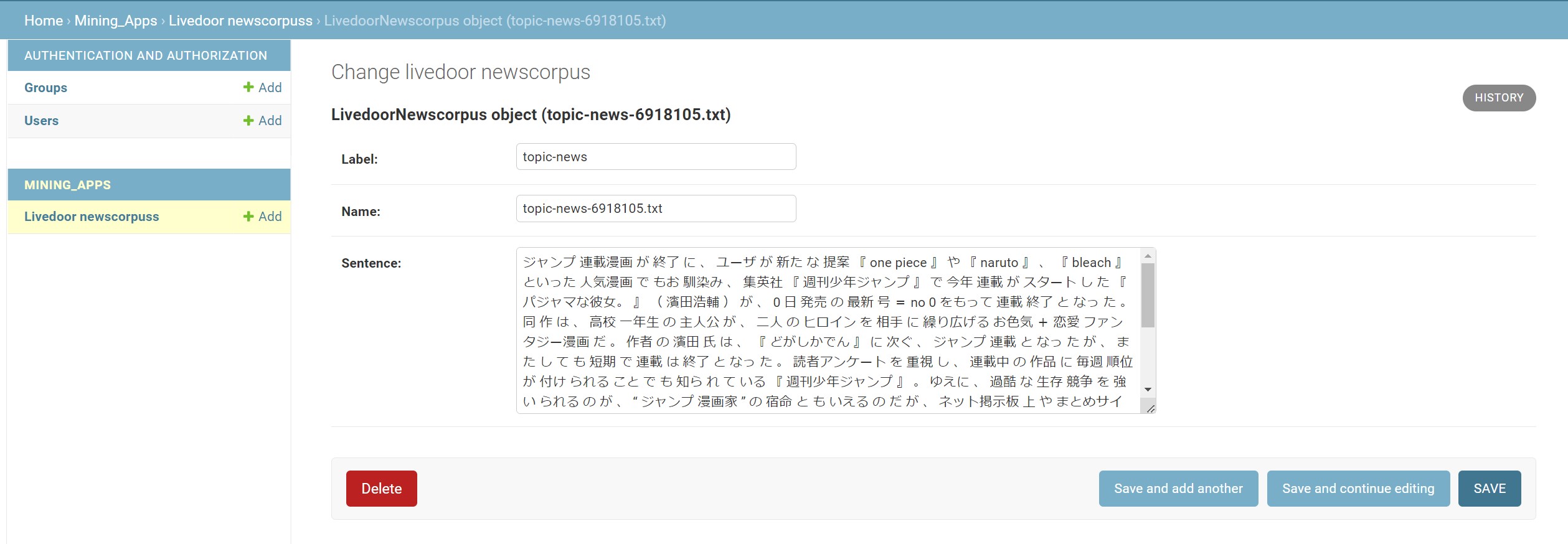
データセット登録画面
データベースにデータを登録する機能です。開発環境ではsqlite3, 本番環境ではpostgresqlを使用しています。
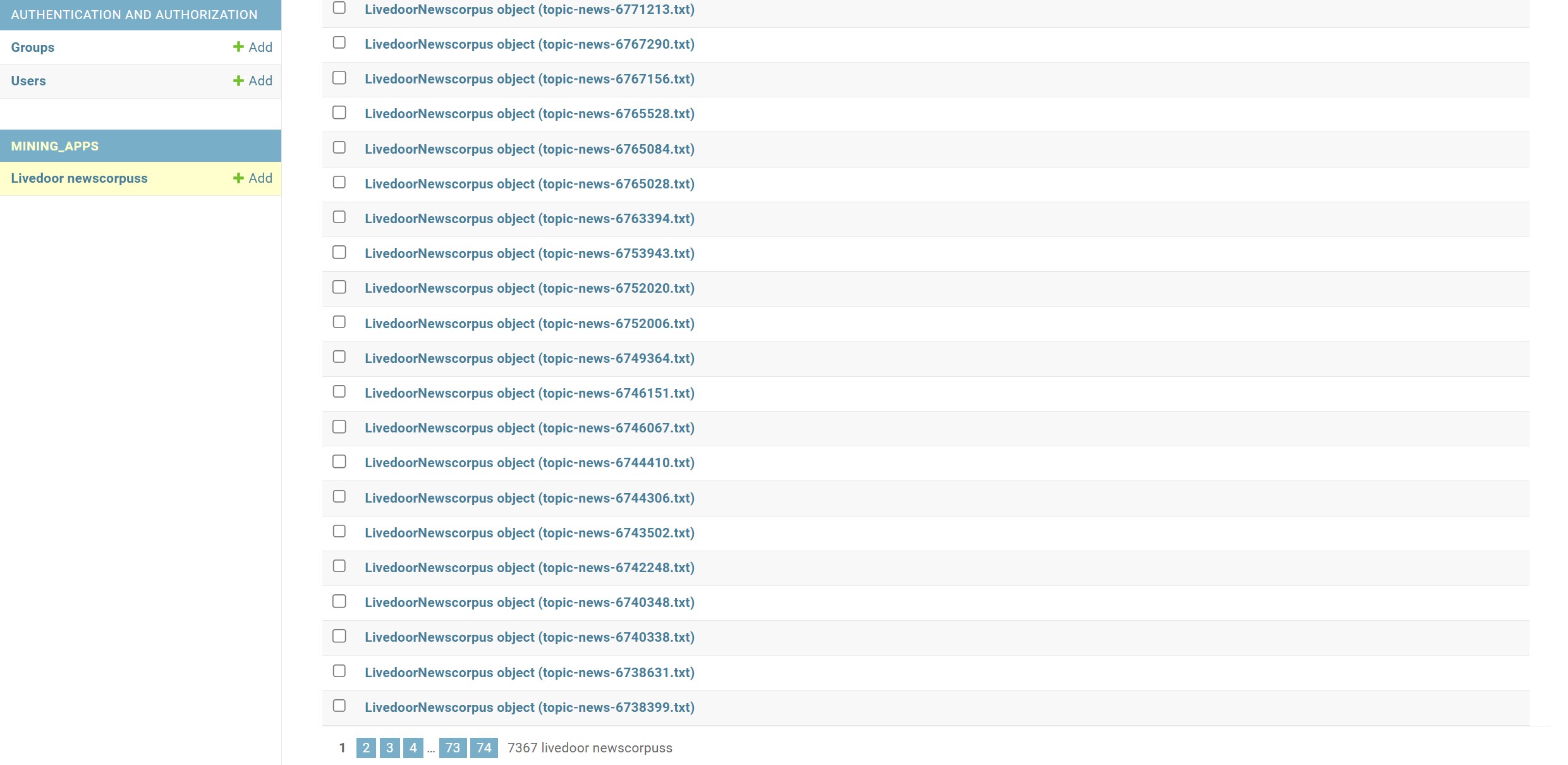
データセット削除画面
登録されているデータセットを削除する機能です。ログイン画面
最初はこの画面になっているためログインしないと使用できません。データセットの二次配布が禁止されているので実装しました。
データベースについて
Django administration というデータベース管理機能を使用しています。
データベースはsqlite3(開発環境)とpostgresql(本番環境)です。
データベースはsqlite3(開発環境)とpostgresql(本番環境)です。
データの保存形式
データリスト
アプリの仕様説明
整形形式
「分かち書きのみ」の場合は何も整形しません。「分かち書き+整形」の場合は以下の処理をして出力します。
- 数字を0に置き換える
- 記号を削除する
- カンマを削除する
- タブを削除する
- 英単語は全て小文字にする
出力形式
以下のフォーマットから選択して出力します。- txt (Text Documents)
- csv (Comma Separated Values )
- tsv (Tab Separated Values )
ファイル名を出力
「Yes」の場合はファイル名を出力します。逆にファイル名は出力したくない場合もあったりするので、その場合は「No」を選択します。
正解ラベルを出力(欠損値なし)
「Yes」の場合は正解ラベルを出力します。「欠損値なし」にしているため全ての正解ラベルが出力されます。
正解ラベルを出力(欠損値あり)
「10%」~「90%」を選択した場合は正解ラベルを出力します。「欠損値あり」にしているため一部の正解ラベルが出力されません。
例えば、選択肢で10%を選択した場合は全データの10%がラベルなしデータとして出力されます。
一部の正解ラベルを隠して学習する半教師あり学習で使用します。
文章を出力
「Yes」の場合は文章を出力します。文章を出力したくない場合はあまりないと思いますが、一応選択肢にしています。
指定されたデータのみ出力
特定のデータだけ出力する場合はファイル名をtxtファイルに記述してアップロードします。以下のように、1行毎に区切ってファイル名を入力
dokujo-tsushin-4782522.txt
dokujo-tsushin-4788373.txt
dokujo-tsushin-4791665.txt
データベースに存在しないファイル名はスルーします。
txt, csv 以外のファイルをアップロードした場合はエラーメッセージを表示します。